
Claude Fable 5 is not just another model launch with a bigger benchmark table. It is a test of whether a frontier AI lab can put near-restricted-class capability into the hands of ordinary paying users while still controlling the tasks it considers too dangerous or strategically sensitive. That makes the release more interesting than the usual race over who is first on a coding score, a reasoning test, or a long-context evaluation.
The model also lands at a moment when AI products are becoming more like operating layers for work. Users are no longer asking only which chatbot gives the nicest answer. They are asking which model can migrate code, analyze messy documents, understand images, run long tasks, and stay useful inside enterprise controls. That is the same shift behind our coverage of OpenAI's broader ChatGPT workspace ambitions and Doubao's move toward task delivery.
Anthropic is framing Fable 5 as the first generally available member of its Mythos class. The important detail is that Fable 5 and Claude Mythos 5 are presented as the same underlying model, but with different access rules. Fable 5 is the public version with safeguards. Mythos 5 is reserved for trusted users in programs such as Project Glasswing, where Anthropic is more willing to expose advanced cybersecurity and biology capabilities under tighter oversight.
Anthropic says Fable 5 exceeds any model it has previously made generally available and describes it as state of the art on nearly all of the benchmarks it tested. The company also says the longer and more complex the task, the larger the model's advantage becomes. That is a meaningful claim because the frontier model market is moving away from short prompt demos and toward durable work sessions where planning, memory, tool use, and error recovery matter.
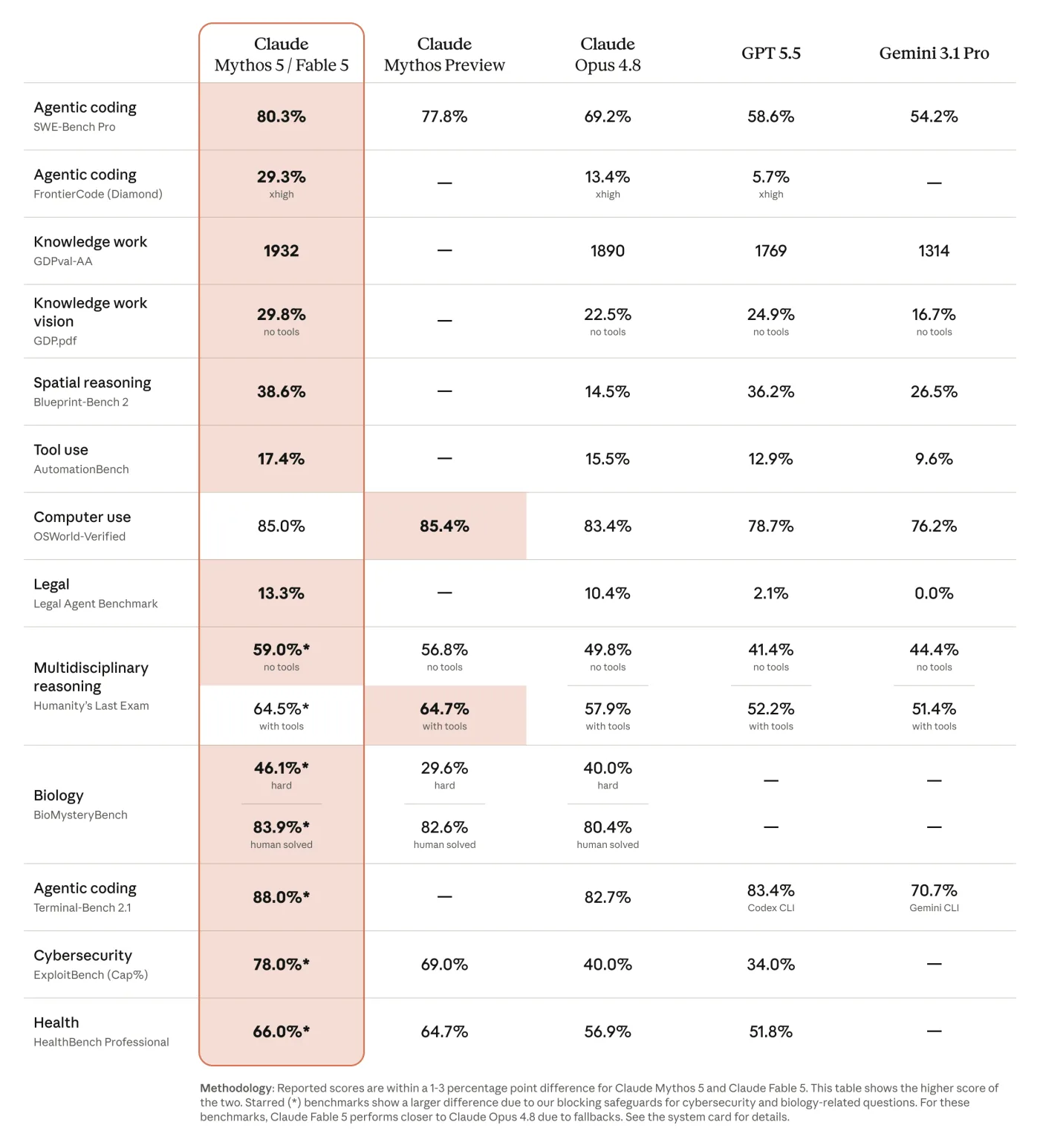
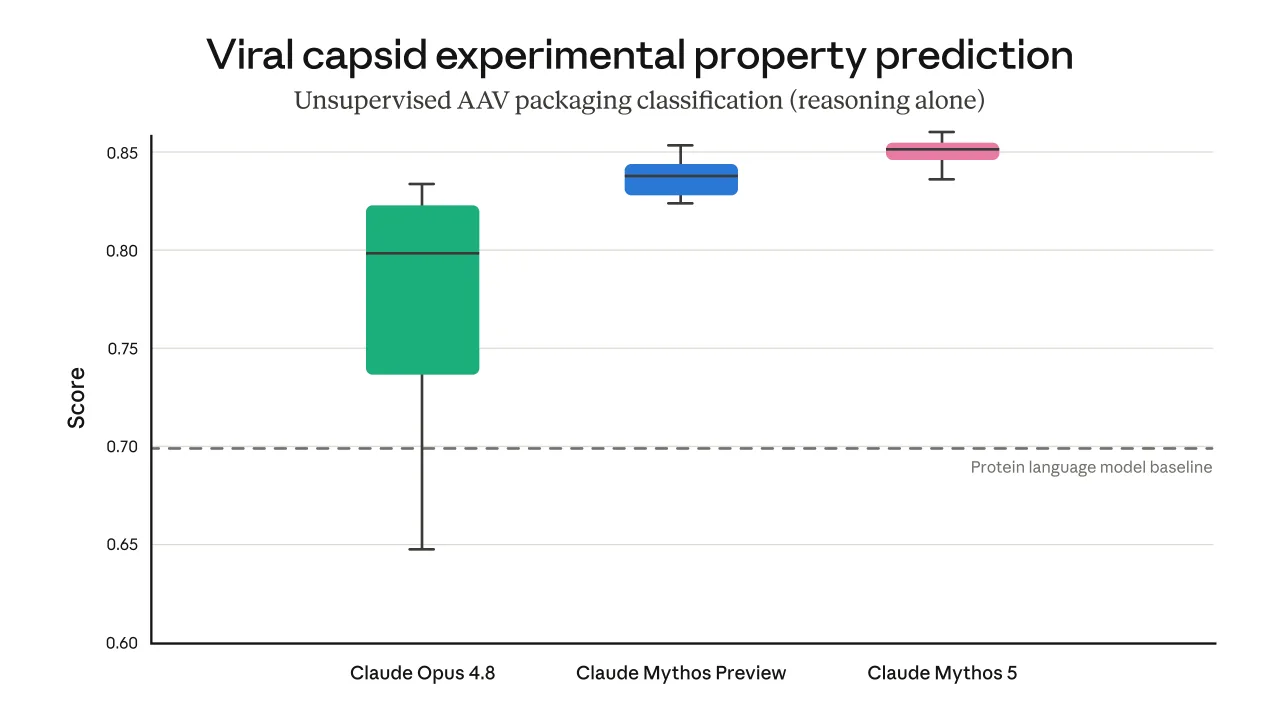
The headline benchmark numbers are strong. Anthropic's table lists Claude Fable 5 and Claude Mythos 5 at 80.3% on SWE-Bench Pro, 88.0% on Terminal-Bench 2.1, 85.0% on OSWorld-Verified, and 59.0% on Humanity's Last Exam without tools. With tools, that Humanity's Last Exam figure rises to 64.5%. The same table also shows 78.0% on ExploitBench capability percentage and 66.0% on HealthBench Professional. Those results put the model in the group of systems that are being judged less like assistants and more like general-purpose workers.
The caveat is that a vendor benchmark table is not the same as broad independent review. It tells us what Anthropic is confident enough to publish, not how Fable 5 will behave across every production workflow. A coding agent can be excellent on structured benchmark tasks and still make expensive mistakes in a real monorepo. A medical or legal answer can score well in a test and still need expert supervision. The benchmark image is still worth including because it shows Anthropic's own positioning: the company wants the market to see Fable 5 as a model that competes at the very top, not as a cautious middle-tier release.
Where the launch becomes unusual is the routing policy. For some requests involving cybersecurity, biology, chemistry, or model distillation, Fable 5 can redirect the user to Claude Opus 4.8 instead of answering directly through the new model. Anthropic says users should be informed when that happens and that the fallback is not expected to affect most ordinary sessions. The practical effect is simple: Fable 5 is available, but not equally available for every kind of frontier work.
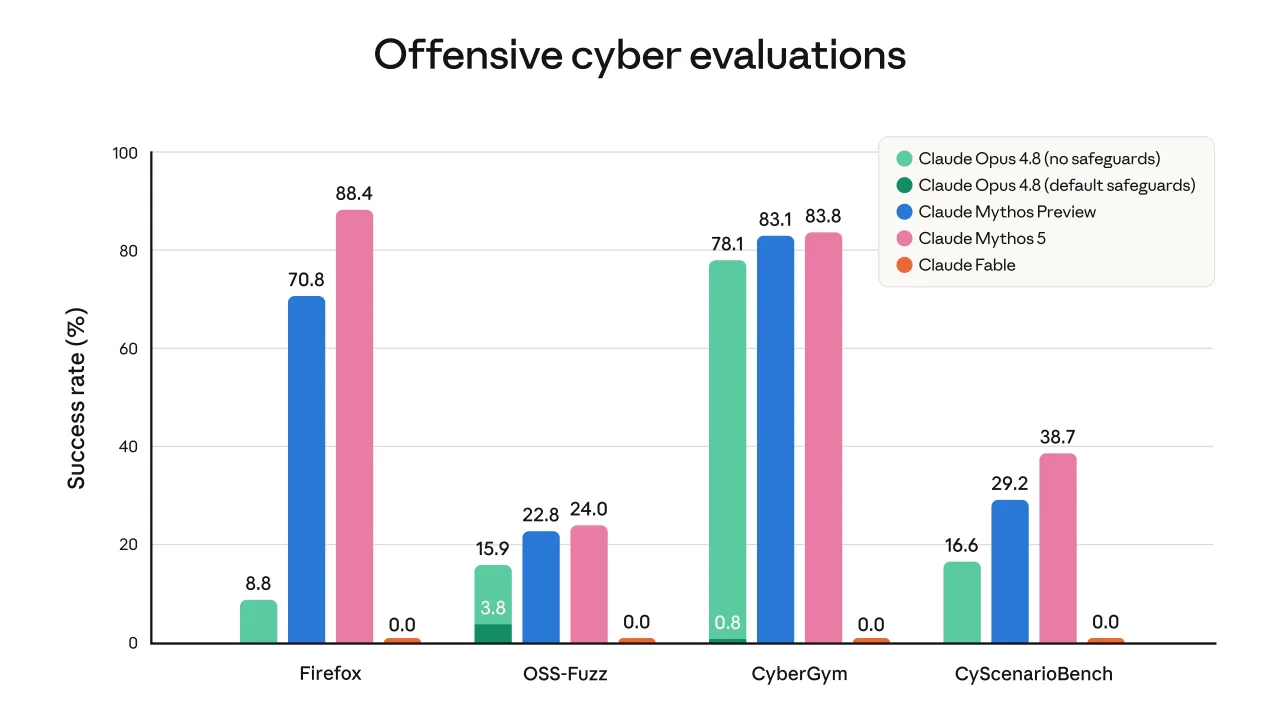
This is the core tension in the release. Anthropic wants credit for making a Mythos-class model broadly usable, but it also wants to preserve a safety boundary around areas where model capability could scale misuse. For most users, that boundary may never appear. For security researchers, biology teams, AI labs, and advanced developers, it may become the defining feature of the product. A model that is excellent until a workflow crosses an invisible line can be hard to operationalize unless the rules are predictable.
The Verge highlighted the same split between public Fable access and the more restricted Mythos 5 channel. That distinction matters because the AI market is no longer only a consumer chatbot market. Enterprises are building model-dependent products, developers are embedding models into coding pipelines, and security teams are using AI to inspect systems. When access changes by task category, buyers need to understand not only average performance, but where the model may refuse, downgrade, or route work elsewhere.
Pricing adds another filter. Fable 5 is listed at $10 per million input tokens and $50 per million output tokens through the API. That is a premium price and it pushes the model into a more deliberate buying category. A developer might use a cheaper model for everyday summarization, support triage, or simple code edits, then reserve Fable 5 for high-value work where the extra cost is easier to justify. This is similar to the way companies already think about cloud AI infrastructure: the best model is not always the model that should handle every task.
Tom's Hardware noted the same cost jump and the free-access window for some subscribers before usage credits become necessary. That creates a short test period where developers and power users can probe the model's strengths, but the long-term question is economic. If Fable 5 is meaningfully better at multi-hour coding, finance analysis, or document-heavy tasks, the price may be acceptable. If users mostly notice restrictions or routing surprises, cheaper rivals will look more attractive.
The launch also raises a data-retention question. Anthropic says Mythos-class models have a 30-day retention policy for prompts and outputs, with the stated purpose of monitoring for misuse and improving safeguards, not training future models. That may be reasonable from a safety perspective, but it is a major governance detail for companies with strict confidentiality requirements. Enterprise AI buyers already care about where data lives, who can inspect it, how long it is stored, and whether contractual privacy terms survive a model upgrade.
Business Insider reported that the Fable and Mythos rollout has produced pushback from parts of the AI industry, especially around restrictions that affect model-development and open-source work. That criticism is not surprising. Safety, competition, and product control are now tangled together. A lab can argue that certain capabilities need containment, while rivals can argue that the same containment protects a closed-model advantage. Both claims can be partly true.
The larger market signal is that frontier AI is splitting into tiers. There will be broadly available models with safeguards, premium models with stricter routing, trusted-access models for sensitive fields, and cheaper models for ordinary volume. The clean benchmark race still matters, but it no longer tells the full story. For companies building on these systems, the practical questions are becoming more specific: what happens when the workflow touches security, biology, proprietary model development, or regulated data?
That is why Fable 5 may be remembered less as a normal release and more as a new template for controlled frontier access. Anthropic is trying to sell capability without giving up its safety posture. Users will decide whether that balance feels like responsible product design or unpredictable gatekeeping. Either way, LLM benchmarks have moved into a new phase. The most powerful model is not judged only by what it can answer, but by when it is allowed to answer, what it costs, and what the provider keeps for review after the session ends.


