Moonshot AI's Kimi K2.7 Code release is aimed at one of the most practical problems in AI coding: long tasks burn tokens quickly. A model that can follow instructions over long context, make fewer unnecessary reasoning detours, and still complete complex coding work is not just nicer to use. It can be cheaper, faster, and easier to integrate into developer workflows. That is why the claim of lower token consumption matters as much as the benchmark gains.
AI coding tools are moving from autocomplete toward longer-running agents. They inspect repositories, modify multiple files, run tests, explain failures, and revise patches. In that setting, overthinking is expensive. A model that spends too many tokens narrating, looping, or exploring weak paths slows the developer down and raises API cost. Kimi K2.7 Code is being positioned as a more disciplined coding model for long-horizon work.
The open-source angle is also important. Developers increasingly want models they can evaluate, route, and deploy with more control. Closed tools are convenient, but open or openly available models let teams test privacy, latency, cost, and customization tradeoffs. That connects to the broader developer-tool competition we have covered in AI model efficiency and speed improvements, where faster and more focused models can be more useful than larger general ones.
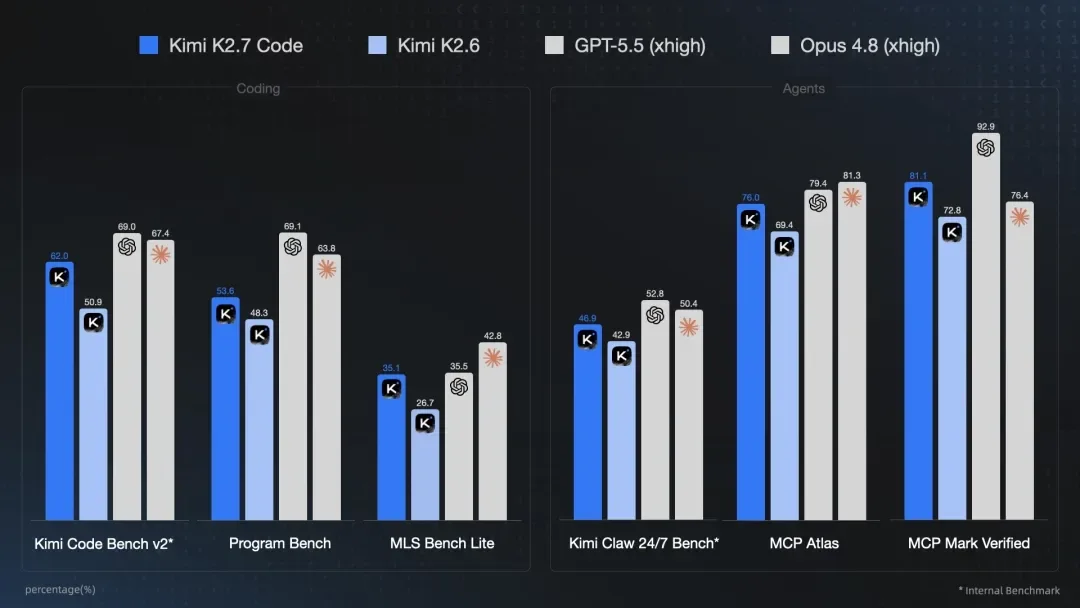
IT Home reports that Kimi K2.7 Code improves instruction following in long-context programming, boosts long-range coding task performance, and reduces average token use by 30 percent compared with K2.6. The report also cites benchmark gains of 21.8 percent on Kimi Code Bench v2, 11 percent on Program-Bench, and 31.5 percent on MLS Bench Lite.
Pricing and access make the release more interesting for teams. The standard input and output prices remain aligned with K2.6, while cached input is cheaper. Kimi Code Plan users are being moved to the new default model, and a faster version is promised with output speeds around five to six times higher than the normal edition in common coding scenarios. If those claims hold in real repositories, the model could become attractive for agentic development workflows.
The caveat is that coding benchmarks do not always predict production usefulness. Real projects have messy dependencies, weak tests, local conventions, and ambiguous product requirements. A coding model has to make changes that fit the codebase, not only solve isolated tasks. Still, Kimi K2.7 Code's emphasis on long context, lower token waste, and open access is directionally right. The next stage of AI coding will be judged less by flashy demos and more by whether models can work through real repositories without wasting time, context, or money.
For engineering teams, the most useful evaluation will be local and boring: point the model at a real backlog item, let it inspect the existing code, and measure how much review time remains. A model that writes fewer unnecessary tokens but produces patches requiring heavy cleanup is not a win. A model that reasons compactly, follows repository conventions, and stops when the task is done can change the economics of AI-assisted development.



